| CONTENTS |
Every now and then, an idea comes along that in retrospect seems just so simple and obvious that everyone wonders why it hadn't been seen all along. Often when that happens, it turns out that the idea isn't really all that new after all. The Java revolution began by drawing on ideas from all the programming languages that came before it. Now, XML—the Extensible Markup Language—is doing for content what Java did for programming: providing a portable language for describing data.
XML is a simple, common format for representing structured information as text. The concept of XML follows the success of HTML as a universal document presentation format and generalizes it to handle any kind of data. In the process, XML has not only recast HTML but is transforming the way that businesses think about their information. In the context of a world driven more and more by documents and data exchange, XML's time has come.
XML and HTML are called markup languages because of the way they add structure to plain-text documents—by surrounding parts of the text with tags that indicate structure or meaning, much as someone with a pen might highlight a sentence and add a note. While HTML predefines a set of tags and their structure, XML is a blank slate in which the author gets to define the tags, the rules, and their meanings.
Both XML and HTML owe their lineage to Standard Generalized Markup Language (SGML)—the mother of all markup languages. SGML has been used in the publishing industry for many years (including at O'Reilly). But it wasn't until the Web captured the world that it came into the mainstream through HTML. HTML started as a very small application of SGML, and if HTML has done anything at all, it has proven that simplicity reigns.
HTML flourished but eventually showed its limitations. Documents using HTML have an unhealthy mix of structural information (such as <head> and <body>) and presentation information (for an egregious example, <blink>). Mixing the model and the user interface in this way limits the usefulness of HTML as a format for data exchange; it's hard for a machine to understand. XML documents consist purely of structure, and it is up to the reader of the document to apply meaning. As we'll see in this chapter, several related languages exist to help interpret and transform XML for presentation or further processing.
When Tim Berners-Lee began postulating the Web back at CERN in the late 1980s, he wanted to organize project information using hypertext.[1] When the Web needed a protocol, HTTP—a simple, text-based client-server protocol—was invented. So what exactly is so enchanting about the idea of plain text? Why, for example, didn't Tim turn to the Microsoft Word format as the basis for Web documents? Surely a binary, non-human-readable format and protocol would be more efficient? Since the Web's inception, there have now been trillions of HTTP transactions. Was it really a good idea for them to use (English) words like "GET" and "POST"?
The answer, as we've all seen, is yes! What humans can read, human developers can work with more easily. There is a time and place for a high level of optimization (and obscurity), but when the goal is universal acceptance and cross-platform portability, simplicity and transparency are paramount. This is the first, fundamental proposition of XML.
Using text to exchange data is not exactly a new idea, either, but historically, for every new document format that came along, a new parser would have to be written. A parser is an application that reads a document and understands its formatting conventions, usually enforcing some rules about the content. For example, the Java Properties class has a parser for the standard properties file format (Chapter 10). In our simple spreadsheet in Chapter 17, we wrote a parser capable of understanding basic mathematical expressions. As we've seen, depending on complexity, parsing can be quite tricky.
With XML, we can represent data without having to write this kind of custom parser. This isn't to say that it's reasonable to use XML for everything (e.g., typing math expressions into our spreadsheet), but for the common types of information that we exchange on the Net, we should no longer have to write parsers that deal with basic syntax and string manipulation. In conjunction with document-verifying components (DTDs or XML Schema), much of the complex error checking is also done automatically. This is the second fundamental proposition of XML.
The APIs we'll discuss in this chapter are powerful and well tested. They are being used around the world to build enterprise-scale systems today. Unfortunately, the current slate of XML tools bundled with Java only partially remove the burden of parsing from the developer. Although we have taken a step up from low-level string manipulation to a common, structured document format, the standard tools still generally require the developer to write low-level code to traverse the content and interpret the string data manually. The resulting program remains somewhat fragile, and much of the work can be tedious. The next step, as we'll discuss briefly later in this chapter, is to begin to use generating tools that read a description of an XML document (an XML DTD or Schema) and generate Java classes or bind existing classes to XML data automatically.
As of Java 1.4, all the basic APIs for working with XML are bundled with Java. This includes the javax.xml standard extension packages for working with Simple API for XML (SAX), Document Object Model (DOM), and Extensible Stylesheet Language (XSL) transforms. If you are using an older version of Java, you can still use all these tools, but you will have to download the packages separately from http://java.sun.com/xml/.
Microsoft's Internet Explorer web browser was the first to support XML explicitly. If you load an XML document in IE 5.0 or greater, it is displayed as a tree using a special stylesheet. The stylesheet uses dynamic HTML to allow you to collapse and expand nodes while viewing the document. IE also supports basic XSL transformation directly in the browser. We'll talk about XSL later in this chapter.
Netscape 6.x and the latest Mozilla browsers also understand XML content and support the rendering of documents using XSL. At the time of this writing, however, they don't offer a friendly viewer by default. You can use the "view source" option to display an XML document in a nicely formatted way. But in general, if you load an XML document into either of these browsers, or any browser that doesn't explicitly transform it, it simply displays the text of the document with all the tags (structural information) stripped off. This is the prescribed behavior for working with XML.
The basic syntax of XML is extremely simple. If you've worked with HTML, you're already halfway there. As with HTML, XML represents information as text using tags to add structure. A tag begins with a name sandwiched between less-than (<) and greater-than (>) characters. Unlike HTML, XML tags must always be balanced; in other words, an opening tag must always be followed by a closing tag. A closing tag looks just like the opening tag but starts with a less-than sign and a slash (</). An opening tag, closing tag, and any content in between are collectively referred to as an element of the XML document. Elements can contain other elements, but they must be properly nested (all tags started within an element must be closed before the element itself is closed). Elements can also contain plain text or a mixture of elements and text. Comments are enclosed between <!-- and --> markers. Here are a few examples:
<!-- Simple -->
<Sentence>This is text.</Sentence>
<!-- Element -->
<Paragraph><Sentence>This is text.</Sentence></Paragraph>
<!-- Mixed -->
<Paragraph>
<Sentence>This <verb>is</verb> text.</Sentence>
</Paragraph>
<!-- Empty -->
<PageBreak></PageBreak>
An empty tag can be written more compactly with a single tag ending with a slash and a greater-than sign (/>):
<PageBreak/>
An XML element can contain attributes, which are simple name-value pairs supplied inside the start tag.
<Document type="LEGAL" ID="42">...</Document> <Image name="truffle.jpg"/>
The attribute value must always be enclosed in quotes. You can use double (") or single (') quotes. Single quotes are useful if the value contains double quotes.
Attributes are intended to be used for simple, unstructured properties or identifiers associated with the element data. It is always possible to make an attribute into a child element, so there is no real need for attributes. But they often make the XML easier to read and more logical. In the case of the Document element in our snippet above, the attributes type and ID represent metadata about the document. We might expect that a Java class representing the Document would have static identifiers for document types such as LEGAL. In the case of the Image element, the attribute is simply a more compact way of including the filename. As a rule, attributes should be atomic, with no significant internal structure; by contrast, child elements can have arbitrary complexity.
An XML document begins with the following header and has one root element:
<?xml version="1.0" encoding="UTF-8"?> <MyDocument> </MyDocument>
The header identifies the version of XML and the character encoding used. The root element is simply the top of the element hierarchy, which can be considered a tree. If you omit this header or have XML text without a single root element, technically what you have is called an XML fragment.
The default encoding for an XML document is UTF-8, the ASCII-friendly 8-bit Unicode encoding. But an XML document may specify an encoding using the encoding attribute of the XML header.
Within an XML document, certain characters are necessarily sacrosanct: for example, the "<" and ">" characters that indicate element tags. When you need to include these in your text, you must encode them. XML provides an escape mechanism called " entities" that allows for encoding special structures. There are five predefined entities in XML, as shown in Table 23-1.
|
Entity |
Encodes |
|---|---|
|
& |
& (ampersand) |
|
< |
< (less than) |
|
> |
> (greater than) |
|
" |
" (quotation mark) |
|
' |
' (apostrophe) |
An alternative to encoding text in this way is to use a special "unparsed" section of text called a character data (CDATA) section. A CDATA section starts with <![CDATA[ and ends with ]]>, like this:
<![CDATA[ Learning Java, O'Reilly & Associates ]]>
The CDATA section looks a little like a comment, but the data is really part of the document, just opaque to the parser.
You've probably seen that HTML has a <body> tag that is used to structure web pages. Suppose for a moment that we are writing XML for a funeral home that also uses the tag <body> for some other, more macabre, purpose. This could be a problem if we want to mix HTML with our mortuary information.
If you consider HTML and the funeral home tags to be a language in this case, the elements (tag names) used in a document are really the vocabulary of those languages. An XML namespace is a way of saying whose dictionary you are using for a given element, allowing us to mix them freely. (Later we'll talk about XML Schema, which enforce the grammar and syntax of the language.)
A namespace is specified with the xmlns attribute, whose value is a Universal Resource Identifier (URI) that uniquely defines the set (and usually the meaning) of tags from that namespace:
<element xmlns="namespaceURI">
Recall from Chapter 13 that a URI is not necessarily a URL. URIs are more general than URLs. In practical terms, a URI is simply to be treated as a unique string. Often, the URI is, in fact, also a URL for a document describing the namespace, but that is only by convention.
An xmlns namespace attribute can be applied to an element and all its children; this is called a default namespace for the element:
<body xmlns="http://funeral-procedures.org/">
But more often it is desirable to specify namespaces on a tag-by-tag basis. To do this, we can use the xmlns attribute to define a special identifier for the namespace and then use that identifier as a prefix on the tags in question. For example:
<funeral xmlns:fun="http://funeral-procedures.org/">
<html><head></head><body>
<fun:body>Corpse #42</fun:body>
</funeral>
In the above snippet of XML, we've qualified the body tag with the prefix "fun:" that we defined in the <funeral> tag. In this case, we should also qualify the root tag as well, reflexively:
<fun:funeral xmlns:fun="http://funeral-procedures.org/">
In the history of XML, support for namespaces is relatively new. Not all parsers support them. To accommodate this, the XML parser factories that we discuss later have a switch to specify whether you want a parser that understands namespaces.
factory.setNamespaceAware(true);
We'll talk more about parsing in the sections on SAX and DOM later in this chapter.
A document that conforms to the basic rules of XML, with proper encoding and balanced tags, is called a well-formed document. Just because a document is syntactically correct doesn't mean that it makes sense, however. Two related specifications, Document Type Definitions (DTDs) and XML Schema, define ways to provide a grammar for your XML elements. This allows you to create syntactic rules, such as "a City element can appear only once inside an Address element." XML Schema goes further to provide a flexible language for describing the validity of data content of the tags, including both simple and compound data types made of numbers and strings. Although XML Schema is the ultimate solution (it includes data validation and not just rules about elements), it is more theory than practice at present, at least in terms of its integration with Java. (We hope that will change soon.)
A document that is checked against a DTD or XML Schema description and follows the rules is called a valid document. A document can be well-formed without being valid, but not vice versa.
To speak very loosely, we could say that the most popular and widely used form of XML in the world today is HTML. The terminology is loose because HTML is not even well-formed XML. HTML tags violate XML's rule forbidding empty elements; the common <p> tag is typically used without a closing tag, for example. HTML attributes also don't require quotes. XML tags are case-sensitive; <P> and <p> are two different tags in XML. We could generously say that HTML is "forgiving" with respect to details like this, but as a developer, you know that sloppy syntax results in ambiguity. XHTML is a version of HTML that is clear and unambiguous. Fortunately, you don't have to manually clean up all your HTML documents; Tidy (http://tidy.sourceforge.net) is an open source program that automatically converts HTML to XHTML, validates it, and corrects common mistakes.
SAX is a low-level, event-style mechanism for parsing XML documents. SAX originated in Java but has been implemented in many languages.
To use SAX, we'll be using classes from the org.xml.sax package, available from the W3C (World Wide Web Consortium). To perform the actual parsing, we'll need the javax.xml.parsers package, which is the standard Java package for accessing XML parsers. The java.xml.parsers package is part of the Java API for XML Processing (JAXP), which allows different parser implementations to be used with Java.
To read an XML document with SAX, we first register an org.xml.sax.ContentHandler class with the parser. The ContentHandler has methods that are called in response to parts of the document. For example, the ContentHandler's startElement() method is called when an opening tag is encountered, and the endElement() method is called when the tag is closed. Attributes are provided with the startElement() call. Text content of elements is passed through a separate method called characters(). The characters() method can be invoked repeatedly to supply more text as it is read, but it often gets the whole string in one bite. The following are the method signatures of these methods of the ContentHandler class.
public void startElement(
String namespace, String localname, String qname, Attributes atts );
public void characters(
char[] ch, int start, int len );
public void endElement(
String namespace, String localname, String qname );
The qname parameter is the qualified name of the element. This is the element name, prefixed with namespace if it has one. When working with namespaces, the namespace and localname parameters are also supplied, providing the namespace and unqualified name.
The ContentHandler interface also contains methods called in response to the start and end of the document, startDocument() and endDocument(), as well as those for handling namespace mapping, special XML instructions, and whitespace that can be ignored. We'll confine ourselves to the three methods above for our examples. As with many other Java interfaces, a simple implementation, org.xml.sax.helpers.DefaultHandler, is provided for us that allows us to override just the methods we're interested in.
To perform the parsing, we'll need to get a parser from the javax.xml.parsers package. The process of getting a parser is abstracted through a factory pattern, allowing different parser implementations to be plugged into the Java platform. The following snippet constructs a SAXParser object and an XMLReader used to parse a file:
import javax.xml.parsers.*; SAXParserFactory factory = SAXParserFactory.newInstance( ); SAXParser saxParser = factory.newSAXParser( ); XMLReader parser = saxParser.getXMLReader( ); parser.setContentHandler( myContentHandler ); parser.parse( myfile.xml" );
You might expect the SAXParser to have the parse method. The XMLReader intermediary was added to support changes in the SAX API between 1.0 and 2.0. Later we'll discuss some options that can be set to govern how XML parsers operate. These options are normally set through methods on the parser factory (e.g., SAXParserFactory) and not the parser itself. This is because the factory may wish to use different implementations to support different required features.
The primary motivation for using SAX instead of the higher-level APIs that we'll discuss later is that it is lightweight and event-driven. SAX doesn't require maintaining the entire document in memory. If, for example, you need to grab the text of just a few elements from a document, or if you need to extract elements from a large stream of XML, you can do so efficiently with SAX. The event-driven nature of SAX also allows you to take actions as the beginning and end tags are parsed. This can be useful for directly manipulating your own models without first going through another representation. The primary weakness of SAX is that you are operating on a tag-by-tag level with no help from the parser to maintain context.
The ContentHandler mechanism for receiving SAX events is very simple. It should be easy to see how one could use it to capture the value or attributes of a single element in a document. What may be harder to see is how one could use SAX to build a real Java object model from an XML document. The following example, SAXModelBuilder, does just that. This example is a bit unusual in that we resort to using reflection to do a job that would otherwise be a burden on the developer. Later, we'll discuss more powerful tools for automatically generating and building models for use with XML documents.
In this section, we'll start by creating some XML along with corresponding Java classes that serve as the model for this XML. We'll see later that it's possible to work with XML more dynamically, without first constructing Java classes that hold all the content, but we want to start out in the most concrete and general way possible. The final step in this example is to create the generic model builder that reads the XML and populates the model classes with their data. The idea here is that the developer is creating only XML and model classes—no custom code—to do the basic parsing.
The first thing we'll need is a nice XML document to parse. Luckily, it's inventory time at the zoo! The following document, zooinventory.xml, describes two of the zoo's residents, including some vital information about their diets:
<?xml version="1.0" encoding="UTF-8"?>
<!-- file zooinventory.xml -->
<Inventory>
<Animal class="mammal">
<Name>Song Fang</Name>
<Species>Giant Panda</Species>
<Habitat>China</Habitat>
<Food>Bamboo</Food>
<Temperament>Friendly</Temperament>
</Animal>
<Animal class="mammal">
<Name>Cocoa</Name>
<Species>Gorilla</Species>
<Habitat>Central Africa</Habitat>
<FoodRecipe>
<Name>Gorilla Chow</Name>
<Ingredient>Fruit</Ingredient>
<Ingredient>Shoots</Ingredient>
<Ingredient>Leaves</Ingredient>
</FoodRecipe>
<Temperament>Know-it-all</Temperament>
</Animal>
</Inventory>
The document is fairly simple. The root element, <Inventory>, contains two <Animal> elements as children. <Animal> contains several simple text elements for things like name, species, and habitat. It also contains either a simple <Food> element or a compound <FoodRecipe> element. Finally, note that the <Animal> element has one attribute (class) that describes the zoological classification of the creature.
Now let's make a Java object model for our zoo inventory. This part is very mechanical—easy, but tedious to do by hand. We simply create objects for each of the complex element types in our XML, using the standard JavaBeans property design patterns ("setters" and "getters") so that our builder can automatically use them later. (We'll prove the usefulness of these patterns later when we see that these same model objects can be understood by the Java XMLEncoder tool.) For convenience, we'll have our model objects extend a base SimpleElement class that handles text content for any element.
public class SimpleElement {
StringBuffer text = new StringBuffer();
public void addText( String s ) { text.append( s ); }
public String getText() { return text.toString(); }
public void setAttributeValue( String name, String value ) {
throw new Error( getClass()+": No attributes allowed");
}
}
public class Inventory extends SimpleElement {
List animals = new ArrayList( );
public void addAnimal( Animal animal ) { animals.add( animal ); }
public List getAnimals( ) { return animals; }
public void setAnimals( List animals ) { this.animals = animals; }
}
public class Animal extends SimpleElement {
public final static int MAMMAL = 1;
int animalClass;
String name, species, habitat, food, temperament;
FoodRecipe foodRecipe;
public void setName( String name ) { this.name = name ; }
public String getName( ) { return name; }
public void setSpecies( String species ) { this.species = species ; }
public String getSpecies( ) { return species; }
public void setHabitat( String habitat ) { this.habitat = habitat ; }
public String getHabitat( ) { return habitat; }
public void setFood( String food ) { this.food = food ; }
public String getFood( ) { return food; }
public void setFoodRecipe( FoodRecipe recipe ) {
this.foodRecipe = recipe; }
public FoodRecipe getFoodRecipe( ) { return foodRecipe; }
public void setTemperament( String temperament ) {
this.temperament = temperament ; }
public String getTemperament( ) { return temperament; }
public void setAnimalClass( int animalClass ) {
this.animalClass = animalClass; }
public int getAnimalClass( ) { return animalClass; }
public void setAttributeValue( String name, String value ) {
if ( name.equals("class") && value.equals("mammal") )
setAnimalClass( MAMMAL );
else
throw new Error("Invalid attribute: "+name);
}
public String toString( ) { return name +"("+species+")"; }
}
public class FoodRecipe extends SimpleElement {
String name;
List ingredients = new ArrayList( );
public void setName( String name ) { this.name = name ; }
public String getName( ) { return name; }
public void addIngredient( String ingredient ) {
ingredients.add( ingredient ); }
public void setIngredients( List ingredients ) {
this.ingredients = ingredients; }
public List getIngredients( ) { return ingredients; }
public String toString() { return name + ": "+ ingredients.toString( ); }
}
If you are working in the NetBeans IDE, you can use the Bean Patterns wizard for your class to help you create all those get and set methods (see Section 21.6.2.1 in Chapter 21 for details).
Now let's get down to business and write our builder tool. The SAXModelBuilder we create in this section receives SAX events from parsing an XML file and constructs classes corresponding to the names of the tags. Our model builder is simple, but it handles the most common structures: elements with text or simple element data. We handle attributes by passing them to the model class, allowing it to map them to fixed identifiers (e.g., Animal.MAMMAL). Here is the code:
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.util.*;
import java.lang.reflect.*;
public class SAXModelBuilder extends DefaultHandler
{
Stack stack = new Stack( );
SimpleElement element;
public void startElement(
String namespace, String localname, String qname, Attributes atts )
throws SAXException
{
SimpleElement element = null;
try {
element = (SimpleElement)Class.forName(qname).newInstance( );
} catch ( Exception e ) {/*No class for element*/}
if ( element == null )
element = new SimpleElement( );
for(int i=0; i<atts.getLength( ); i++)
element.setAttributeValue( atts.getQName(i), atts.getValue(i) );
stack.push( element );
}
public void endElement( String namespace, String localname, String qname)
throws SAXException
{
element = (SimpleElement)stack.pop( );
if ( !stack.empty( ) )
try {
setProperty( qname, stack.peek( ), element );
} catch ( Exception e ) { throw new SAXException( "Error: "+e ); }
}
public void characters(char[] ch, int start, int len ) {
String text = new String( ch, start, len );
((SimpleElement)(stack.peek( ))).addText( text );
}
void setProperty( String name, Object target, Object value )
throws SAXException
{
Method method = null;
try {
method = target.getClass( ).getMethod(
"add"+name, new Class[] { value.getClass( ) } );
} catch ( NoSuchMethodException e ) { }
if ( method == null ) try {
method = target.getClass( ).getMethod(
"set"+name, new Class[] { value.getClass( ) } );
} catch ( NoSuchMethodException e ) { }
if ( method == null ) try {
value = ((SimpleElement)value).getText( );
method = target.getClass( ).getMethod(
"add"+name, new Class[] { String.class } );
} catch ( NoSuchMethodException e ) { }
try {
if ( method == null )
method = target.getClass( ).getMethod(
"set"+name, new Class[] { String.class } );
method.invoke( target, new Object [] { value } );
} catch ( Exception e ) { throw new SAXException( e.toString( ) ); }
}
public SimpleElement getModel( ) { return element; }
}
The SAXModelBuilder extends DefaultHandler to help us implement the ContentHandler interface. We use the startElement(), endElement(), and characters() methods to receive information from the document.
Because SAX events follow the structure of the XML document, we use a simple stack to keep track of which object we are currently parsing. At the start of each element, the model builder attempts to create an instance of a class with the same name and push it onto the top of the stack. Each nested opening tag creates a new object on the stack until we encounter a closing tag. Upon reaching an end of the element, we pop the current object off the stack and attempt to apply its value to its parent (the enclosing element), which is the new top of the stack. The final closing tag leaves the stack empty, but we save the last value in the result variable.
Our setProperty() method uses reflection and the standard JavaBeans naming conventions to look for the appropriate property "setter" method to apply a value to its parent object. First we check for a method named add<Property> or set<Property>, accepting an argument of the child element type (for example, the addAnimal( Animal animal ) method of our Inventory object). Failing that, we look for an "add" or "set" method accepting a String argument and use it to apply any text content of the child object. This convenience saves us from having to create trivial classes for properties containing only text.
The common base class SimpleElement helps us in two ways. First, it provides a method allowing us to pass attributes to the model class. Next, we use SimpleElement as a placeholder when no class exists for an element, allowing us to store the text of the tag.
Finally, we can test-drive the model builder with the following class, TestModelBuilder, which calls the SAX parser, setting an instance of our SAXModelBuilder as the content handler. The test class then prints some of the information parsed from the zooinventory.xml file:
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class TestModelBuilder
{
public static void main( String [] args ) throws Exception
{
SAXParserFactory factory = SAXParserFactory.newInstance( );
SAXParser saxParser = factory.newSAXParser( );
XMLReader parser = saxParser.getXMLReader( );
SAXModelBuilder mb = new SAXModelBuilder( );
parser.setContentHandler( mb );
parser.parse( "zooinventory.xml" );
Inventory inventory = (Inventory)mb.getModel( );
System.out.println("Animals = "+inventory.getAnimals( ));
Animal cocoa = (Animal)(inventory.getAnimals( ).get(1));
FoodRecipe recipe = cocoa.getFoodRecipe( );
System.out.println( "Recipe = "+recipe );
}
}
The output should look like this:
Animals = [Song Fang(Giant Panda), Cocoa(Gorilla)] Recipe = Gorilla Chow: [Fruit, Shoots, Leaves]
In the following sections we'll generate the equivalent output using different tools.
To make our model builder more complete, we could use more robust naming conventions for our tags and model classes (taking into account packages and mixed capitalization, etc.). But more generally, we might not want to name our model classes strictly based on tag names. And, of course, there is the problem of taking our model and going the other way, using it to generate an XML document. Furthermore, as we've said, writing the model classes is tedious and error-prone. All this is a good indication that this area is ripe for autogeneration of classes. We'll discuss tools that do that a bit later in the chapter.
Java 1.4 introduced a tool for serializing JavaBeans classes to XML. The java.beans package XMLEncoder and XMLDecoder classes are analogous to java.io ObjectInputStream and ObjectOutputStream. Instead of using the native Java serialization format, they store the object state in a high-level XML format. We say that they are analogous, but the XML encoder is not a general replacement for Java object serialization. Instead, it is specialized to work with objects that follow the JavaBeans design patterns, and it can only store and recover state of the object that is expressed through a bean's public properties in this way (using getters and setters).
In memory, the XMLEncoder attempts to construct a copy of the graph of beans that you are serializing, using only public constructors and JavaBean properties. As it works, it writes out these steps as "instructions" in an XML format. Later, the XMLDecoder executes these instructions and produces the result. The primary advantage of this process is that it is highly resilient to changes in the class implementation. While standard Java object serialization can accommodate many kinds of "compatible changes" in classes, it requires some help from the developer to get it right. Because the XMLEncoder uses only public APIs and writes instructions in simple XML, it is expected that this form of serialization will be the most robust way to store the state of JavaBeans. The process is referred to as "long-term persistence" for JavaBeans.
Give it a whirl. You can use the model-builder example to create the beans and compare the output to our original XML. You can add this bit to our TestModelBuilder class, which will populate the beans for you to write:
import java.beans.XMLEncoder; XMLEncoder xmle = new XMLEncoder( System.out ); xmle.writeObject(inventory); xmle.close( );
Fun!
It might seem at first like this would obviate the need for our SAXModelBuilder example. Why not simply write our XML in the format that XMLDecoder understands and use it to build our model? Well, although XMLEncoder is very efficient at eliminating redundancy, you can see that its output is still very verbose (about four times as large as our original XML) and not very human-friendly. Although it's possible to write it by hand, this XML format wasn't really designed for that. Finally, although XMLEncoder can be customized for how it handles specific object types, it suffers from the same problem that our model builder does in that "binding" (the namespace of tags) is determined strictly by our Java class names. As we've said before, what is really needed is a more general tool to generate classes or to map our own classes to XML and back.
In the last section, we used SAX to parse an XML document and build a Java object model representing it. In that case, we created specific Java types for each of our complex elements. If we were planning to use our model extensively in an application, this technique would give us a great deal of flexibility. But often it is sufficient (and much easier) to use a "generic" model that simply represents the content of the XML in a neutral form. The Document Object Model (DOM) is just that. The DOM API parses an XML document into a full, memory-resident representation consisting of classes such as Element and Attributes with text values.
As we saw in our zoo example, once you have an object model, using the data is a breeze. So a generic DOM would seem like an appealing solution, especially when working mainly with text. The only catch in this case is that DOM didn't evolve first as a Java API, and it doesn't map well to Java. DOM is very complete and provides access to every facet of the original XML document, but it's so generic (and language-neutral), it's cumbersome to use in Java. In our example, we'll start by making a couple of helper methods to smooth things over. Later, we'll also mention a native Java alternative to DOM called JDOM that is more pleasant to use.
The core DOM classes belong to the org.w3c.dom package. The result of parsing an XML document with DOM is a Document object from this package (see Figure 23-1). The Document is a factory and a container for a hierarchical collection of Node objects, representing the document structure. A node has a parent and may have children, which can be traversed using its getChildNodes(), getFirstChild(), or getLastChild() methods. A node may also have "attributes" associated with it, which consist of a named map of nodes.
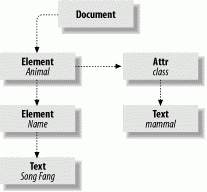
Subtypes of Node—Element, Text, and Attr—represent elements, text, and attributes in XML. Some types of nodes (including these) have a text "value." For example, the value of a Text node is the text of the element it represents. The same is true of an attribute, cdata, or comment node. The value of a node can be accessed by the getNodeValue() and setNodeValue() methods.
The Element node provides "random" access to its child elements through its getElementsByTagName() method, which returns a NodeList (a simple collection type). You can also fetch an attribute by name from the Element using the getAttribute() method.
The javax.xml.parsers package contains a factory for DOM parsers, just as it does for SAX parsers. An instance of DocumentBuilderFactory can be used to create a DocumentBuilder object to parse the file and produce a Document result.
Let's use DOM to parse our zoo inventory and print the same information as our model-builder example. Using DOM saves us from having to create all those model classes and makes our example much shorter. But before we even begin, we're going to make a couple of utility methods to save us a great deal of pain. The following class, DOMUtil, covers two very common operations on an element: retrieving a simple (singular) child element by name and retrieving the text of a simple child element by name. Here is the code:
import org.w3c.dom.*;
public class DOMUtil
{
public static Element getFirstElement( Element element, String name ) {
NodeList nl = element.getElementsByTagName( name );
if ( nl.getLength() < 1 )
throw new RuntimeException(
"Element: "+element+" does not contain: "+name);
return (Element)nl.item(0);
}
public static String getSimpleElementText( Element node, String name )
{
Element namedElement = getFirstElement( node, name );
return getSimpleElementText( namedElement );
}
public static String getSimpleElementText( Element node )
{
StringBuffer sb = new StringBuffer();
NodeList children = node.getChildNodes();
for(int i=0; i<children.getLength(); i++) {
Node child = children.item(i);
if ( child instanceof Text )
sb.append( child.getNodeValue() );
}
return sb.toString();
}
}
With that out of the way we can present our TestDOM class:
mport javax.xml.parsers.*;
import org.w3c.dom.*;
public class TestDOM
{
public static void main( String [] args ) throws Exception
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder parser = factory.newDocumentBuilder();
Document document = parser.parse( "zooinventory.xml" );
Element inventory = document.getDocumentElement();
NodeList animals = inventory.getElementsByTagName("Animal");
System.out.println("Animals = ");
for( int i=0; i<animals.getLength(); i++ ) {
String name = DOMUtil.getSimpleElementText(
(Element)animals.item(i),"Name" );
String species = DOMUtil.getSimpleElementText(
(Element)animals.item(i), "Species" );
System.out.println( " "+ name +" ("+species+")" );
}
Element foodRecipe = DOMUtil.getFirstElement(
(Element)animals.item(1), "FoodRecipe" );
String name = DOMUtil.getSimpleElementText( foodRecipe, "Name" );
System.out.println("Recipe = " + name );
NodeList ingredients = foodRecipe.getElementsByTagName("Ingredient");
for(int i=0; i<ingredients.getLength(); i++)
System.out.println( " " + DOMUtil.getSimpleElementText(
(Element)ingredients.item(i) ) );
}
}
TestDOM creates an instance of a DocumentBuilder and uses it to parse our zooinventory.xml file. We use the Document getDocumentElement() method to get the root element of the document, from which we will begin our traversal. From there, we ask for all the Animal child nodes. The getElementbyTagName() method returns a NodeList object, which we then use to iterate through our creatures. For each animal, we use our DOMUtil.getSimpleElementText() method to retrieve the basic name and species information. Next, we use the DOMUtil.getFirstElement() method to retrieve the element called FoodRecipe from the second animal. We use it to fetch a NodeList for the tags matching Ingredient and print them as before. The output should contain the same information as our SAX-based example.
Thus far, we've used the SAX and DOM APIs to parse XML. But what about generating XML? Sure, it's easy to generate trivial XML documents simply by emitting the appropriate strings. But if we plan to create a complex document on the fly, we might want some help with all those quotes and closing tags. What we can do is to build a DOM representation of our object in memory and then transform it to text. This is also useful if we want to read a document and then make some alterations to it. To do this, we'll use of the java.xml.transform package. This package does a lot more than just printing XML. As its name implies, it's part of a general transformation facility. It includes the XSL/XSLT languages for generating one XML document from another. (We'll talk about XSL later in this chapter.)
We won't discuss the details of constructing a DOM in memory here, but it follows fairly naturally from what you've learned about traversing the tree in our previous example. The following example, PrintDOM, simply parses our zooinventory.xml file to a DOM and then prints it back to the screen:
import javax.xml.parsers.*;
import org.w3c.dom.*;
import javax.xml.transform.*;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
public class PrintDOM {
public static void main( String [] args ) throws Exception
{
DocumentBuilder parser =
DocumentBuilderFactory.newInstance().newDocumentBuilder( );
Document document=parser.parse( "zooinventory.xml" );
Transformer transformer =
TransformerFactory.newInstance().newTransformer( );
Source source = new DOMSource( document );
Result output = new StreamResult( System.out );
transformer.transform( source, output );
}
}
Note that the imports are almost as long as the entire program! Here we are using an instance of a Transformer object in its simplest capacity to copy from a source to an output. We'll return to the Transformer later when we discuss XSL.
As we promised earlier, we'll now describe an easier DOM API: JDOM, created by Jason Hunter and Brett McLaughlin, two fellow O'Reilly authors (Java Servlet Programming and Java and XML, respectively). It is a more natural Java DOM that uses real Java collection types such as List for its hierarchy and provides more streamlined methods for building documents. You can get the latest JDOM from http://www.jdom.org/. Here's the JDOM version of our standard "test" program:
import org.jdom.*;
import org.jdom.input.*;
import org.jdom.output.*;
import java.util.*;
public class TestJDOM {
public static void main( String[] args ) throws Exception {
Document doc = new SAXBuilder( ).build("zooinventory.xml");
List animals = doc.getRootElement( ).getChildren("Animal");
System.out.println("Animals = ");
for( int i=0; i<animals.size( ); i++ ) {
String name = ((Element)animals.get(i)).getChildText("Name");
String species = ((Element)animals.get(i)).getChildText("Species");
System.out.println( " "+ name +" ("+species+")" );
}
Element foodRecipe = ((Element)animals.get(1)).getChild("FoodRecipe");
String name = foodRecipe.getChildText("Name");
System.out.println("Recipe = " + name );
List ingredients = foodRecipe.getChildren("Ingredient");
for(int i=0; i<ingredients.size( ); i++)
System.out.println( " "+((Element)ingredients.get(i)).getText( ) );
}
}
JDOM has convenience methods that take the place of our homemade DOM helper methods. Namely, the JDOM element has getChild() and getChildren() methods as well as a getChildText() method for retrieving node text.
"Words, words, mere words, no matter from the heart."
—William Shakespeare, Troilus and Cressida
In this section, we talk about DTDs and XML Schema, two ways to enforce rules an XML document must follow. A DTD is a grammar for an XML document, defining which tags may appear where and in what order, with what attributes, etc. XML Schema is the next generation of DTD. With XML Schema, you can describe the data content of the document in terms of primitives such as numbers, dates, and simple regular expressions. The word schema means a blueprint or plan for structure, so we'll refer to DTDs and XML Schema collectively as schema where either applies
Now for a reality check. Unfortunately, Java support for XML Schema isn't entirely mature at the time of this writing. XML support in Java 1.4.0 is based on the Apache Project's Crimson parser (which in turn is based on Sun's "Project X" parser). The Crimson engine doesn't support XML Schema. However, a future release of Java will migrate the XML implementation to the Apache Xerces2 engine, and at that time, XML Schema should begin to be supported.
XML's validation of documents is a key piece of what makes it useful as a data format. Using a schema is somewhat analogous to the way Java classes enforce type checking in the language. Schema define document types. Documents conforming to a given schema are often referred to as instance documents.
This type safety provides a layer of protection that eliminates having to write complex error-checking code. However, validation may not be necessary in every environment. For example, when the same tool generates XML and reads it back, validation should not be necessary in normal operation. It is invaluable, though, during development. Often, document validation is used during development and turned off in production environments.
The Document Type Definition language is fairly simple. A DTD is primarily a set of special tags that define each element in the document and, for complex types, provide a list of the elements it may contain. The DTD <!ELEMENT> tag consists of the name of the tag and either a special keyword for the data type or a parenthesized list of elements.
<!ELEMENT Name ( #PCDATA )> <!ELEMENT Document ( Head, Body )>
The special identifier #PCDATA indicates character data (a string). When a list is provided, the elements are expected to appear in that order. The list may contain sublists, and items may be made optional using a vertical bar (|) as an OR operator. Special notation can also be used to indicate how many of each item may appear; a few examples of this notation are shown in Table 23-2.
|
Character |
Meaning |
|---|---|
|
* |
Zero or more occurrences |
|
? |
Zero or one occurrences |
|
+ |
One or more occurrences |
Attributes of an element are defined with the <!ATTLIST> tag. This tag enables the DTD to enforce rules about attributes. It accepts a list of identifiers and a default value:
<!ATTLIST Animal class (unknown | mammal | reptile) "unknown">
This ATTLIST says that the Animal element has a class attribute that can have one of three values: unknown, mammal, or reptile. The default is unknown.
We won't cover everything you can do with DTDs here. But the following example will guarantee zooinventory.xml follows the format we've described. Place the following in a file called zooinventory.dtd (or grab this file from the CD-ROM or web site for the book):
<!ELEMENT Inventory ( Animal* )> <!ELEMENT Animal (Name, Species, Habitat, (Food | FoodRecipe), Temperament)> <!ATTLIST Animal class (unknown | mammal | reptile) "unknown"> <!ELEMENT Name ( #PCDATA )> <!ELEMENT Species ( #PCDATA )> <!ELEMENT Habitat ( #PCDATA )> <!ELEMENT Food ( #PCDATA )> <!ELEMENT FoodRecipe ( Name, Ingredient+ )> <!ELEMENT Ingredient ( #PCDATA )> <!ELEMENT Temperament ( #PCDATA )>
The DTD says that an Inventory consists of any number of Animal elements. An Animal has a Name, Species, and Habitat tag followed by either a Food or FoodRecipe. FoodRecipe's structure is further defined later.
To use our DTD, we must associate it with the XML document. We do this by placing a DOCTYPE declaration in the XML itself. When a validating parser encounters the DOCTYPE, it attempts to load the DTD and validate the document. There are several forms the DOCTYPE can have, but the one we'll use is:
<!DOCTYPE Inventory SYSTEM "zooinventory.dtd">
Both SAX and DOM parsers can automatically validate documents that contain a DOCTYPE declaration. However, you have to explicitly ask the parser factory to provide a parser that is capable of validation. To do this, set the validating property of the parser factory to true before you ask it for an instance of the parser. For example:
SAXParserFactory factory = SAXParserFactory.newInstance( ); factory.setValidating( true );
Try inserting the setValidating( ) line in our model builder example at the location indicated above. Now abuse the zooinventory.xml file by adding or removing an element or attribute and see what happens when you run the example.
To really use the validation, we would have to register an org.xml.sax.ErrorHandler object with the parser, but by default Java installs one that simply prints the errors for us.
Although DTDs can define the basic structure of an XML document, they can't adequately describe data and validate it programmatically. The evolving XML Schema standard is the next logical step and should replace DTDs in the near future. For more information about XML Schema, see http://www.w3.org/XML/Schema. As mentioned earlier, we expect an upcoming Java release to support XML Schema.
The ultimate goal of XML will be reached by automated binding of XML to Java classes. There are several tools today that provide this, but they are hampered by the slow adoption of XML Schema.
The standard Java solution is the forthcoming Java XML Binding (JAXB) project. Unfortunately, at the time of this writing, JAXB is not mature. It is difficult to use and doesn't support XML Schema (necessary to fully describe document content). JAXB also requires its own "binding" language to be used, even for simple cases. We hope that the final release of JAXB will provide a good solution for XML binding. You can find information about JAXB at http://java.sun.com/xml/jaxb.
Unlike JAXB, Castor, an open source XML binding framework for Java, works with XML Schema and is relatively easy to use. Unfortunately, at the time of this writing, Castor doesn't support DTDs, and most industry- or task-specific XML standards are still written in terms of DTDs. You can find out more about Castor at http://www.castor.org/.
Earlier in this chapter, we used a Transformer object to copy a DOM representation of an example back to XML text. We mentioned then that we were not really tapping the potential of the Transformer. Now we'll give you the full story.
The javax.xml.transform package is the API for using the XSL/XSLT transformation language. XSL stands for Extensible Stylesheet Language. Like Cascading Stylesheets for HTML, XSL allows us to "mark up" XML documents by adding tags that provide presentation information. XSL Transformation (XSLT) takes this further by adding the ability to completely restructure the XML and produce arbitrary output. XSL and XSLT together comprise their own programming language for processing an XML document as input and producing another (usually XML) document as output. (From here on in we'll refer to them collectively as XSL.)
XSL is extremely powerful, and new applications for its use arise every day. For example, consider a web portal that is frequently updated and which must provide access to a variety of mobile devices, from PDAs to cell phones to traditional browsers. Rather than recreating the site for these and additional platforms, XSL can transform the content to an appropriate format for each platform. Multilingual sites also benefit from XSL.
You can probably guess the caveat that we're going to issue next: XSL is a big topic worthy of its own books (see, for example, O'Reilly's Java and XSLT by Eric Burke, a fellow St. Louis author), and we can only give you a taste of it here. Furthermore, some people find XSL difficult to understand at first glance because it requires thinking in terms of recursively processing document tags. Don't be put off if you have trouble following this example; just file it away and return to it when you need it. At some point, you will be interested in the power transformation can offer you.
XSL is an XML-based standard, so it should come as no surprise that the language is based on XML. An XSL stylesheet is an XML document using special tags defined by the XSL namespace to describe the transformation. The most basic XSL operations include matching parts of the input XML document and generating output based on their contents. One or more XSL templates live within the stylesheet and are called in response to tags appearing in the input. XSL is often used in a purely input-driven way, where input XML tags trigger output in the order that they appear, using only the information they contain. But more generally, the output can be constructed from arbitrary parts of the input, drawing from it like a database, composing elements and attributes. The XSLT transformation part of XSL adds things like conditionals and for loops to this mix, enabling arbitrary output to be generated based on the input.
An XSL stylesheet contains as its root element a stylesheet tag. By convention, the stylesheet defines a namespace prefix xsl for the XSL namespace. Within the stylesheet are one or more template tags containing a match attribute describing the element upon which they operate.
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="/">
I found the root of the document!
</xsl:template>
</xsl:stylesheet>
When a template matches an element, it has an opportunity to handle all the children of the element. The simple stylesheet above has one template that matches the root of the input document and simply outputs some plain text. By default, input not matched is simply copied to the output with its tags stripped (HTML convention). But here we match the root so we consume the entire input.
The match attribute can refer to elements in a hierarchical path fashion starting with the root. For example, match="/Inventory/Animal" would match only the Animal elements from our zooinventory.xml file. The path may be absolute (starting with "/") or relative, in which case the template detects whenever that element appears in any context. The match attribute actually uses an expression format called XPath that allows you to describe element names using a syntax somewhat similar to a regular expression. XPath is a powerful syntax for describing sets of nodes in XML, and it includes notation for describing sets of child nodes based on path and even attributes.
Within the template, we can put whatever we want, as long as it is well-formed XML (if not, we can use a CDATA section). But the real power comes when we use parts of the input to generate output. The XSL value-of tag is used to output the content of an element or a child of the element. For example, the following template would match an Animal element and output the value of its Name child:
<xsl:template match="Animal"> Name: <xsl:value-of select="Name"/> </xsl:template>
The select attribute uses a similar expression format to match. Here we tell it to print the value of the Name element within Animal. We could have used a relative path to a more deeply nested element within Animal or even an absolute path to another part of the document. To refer to its own element, we can simply use "." as the path. The select expression can also retrieve attributes from the elements it refers to.
Now if we try to add the Animal template to our simple example, it won't generate any output. What's the problem? Well, if you recall, we said that a template matching an element has the opportunity to process all its children. We already have a template matching the root ("/"), so it is consuming all the input. The answer to our dilemma—and this is where things get a little tricky—is to delegate the matching to other templates using the apply-templates tag. The following example correctly prints the names of all the animals in our document:
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="/">
Found the root!
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="Animal">
Name: <xsl:value-of select="Name"/>
</xsl:template>
</xsl:stylesheet>
Note that we still have the opportunity to add output before and after the apply-templates tag. But upon invoking it, the template matching continues from the current node. Next we'll use what we have so far and add a few bells and whistles.
Your boss just called, and it's now imperative that your zoo clients have access to the zoo inventory through the Web, today! Well, after reading Chapter 14, you should be thoroughly prepared to build a nice "zoo portal." Let's get you started by creating an XSL stylesheet to turn our zooinventory.xml into HTML:
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="/Inventory">
<html><head><title>Zoo Inventory</title></head>
<body><h1>Zoo Inventory</h1>
<table border="1">
<tr><td><b>Name</b></td><td><b>Species</b></td>
<td><b>Habitat</b></td><td><b>Temperament</b></td>
<td><b>Diet</b></td></tr>
<xsl:apply-templates/>
<!-- Process Inventory -->
</table>
</body>
</html>
</xsl:template>
<xsl:template match="Inventory/Animal">
<tr><td><xsl:value-of select="Name"/></td>
<td><xsl:value-of select="Species"/></td>
<td><xsl:value-of select="Habitat"/></td>
<td><xsl:value-of select="Temperament"/></td>
<td><xsl:apply-templates select="Food|FoodRecipe"/>
<!-- Process Food,FoodRecipe--></td></tr>
</xsl:template>
<xsl:template match="FoodRecipe">
<table>
<tr><td><em><xsl:value-of select="Name"/></em></td></tr>
<xsl:for-each select="Ingredient">
<tr><td><xsl:value-of select="."/></td></tr>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>
The stylesheet contains three templates. The first matches /Inventory and outputs the beginning of our HTML document (the header) along with the start of a table for the animals. It then delegates using apply-templates before closing the table and adding the HTML footer. The next template matches Inventory/Animal, printing one row of an HTML table for each animal. Although there are no other Animal elements in the document, it still doesn't hurt to specify that we will match an Animal only in the context of an Inventory, because in this case we are relying on Animal to start and end our table. (This template makes sense only in the context of an Inventory.) Finally, we provide a template that matches FoodRecipe and prints a small (nested) table for that information. FoodRecipe makes use of the for-each operation to loop over child nodes with a select specifying that we are only interested in Ingredient children. For each Ingredient, we output its value in a row.
There is one more thing to note in the Animal template. Our apply-templates element has a select attribute that limits the elements affected. In this case, we are using the "|" regular expression-like syntax to say that we want to apply templates for only the Food or FoodRecipe child elements. Why do we do this? Because we didn't match the root of the document (only Inventory), we still have the default stylesheet behavior of outputting the plain text of nodes that aren't matched. We want this behavior for the Food element in the event that a FoodRecipe isn't there. But we don't want it for all the other elements of Animal that we've handled explicitly. Alternatively, we could have been more verbose, adding a template matching the root and another template just for the Food element. That would also mean that new tags added to our XML would be ignored and not change the output. This may or may not be the behavior you want, and there are other options as well. As with all powerful tools, there is usually more than one way to do something.
Now that we have a stylesheet, let's apply it! The following simple program, XSLTransform, uses the javax.xml.transform package to apply the stylesheet to an XML document and print the result. You can use it to experiment with XSL and our example code.
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
public class XSLTransform
{
public static void main( String [] args ) throws Exception
{
if ( args.length < 2 || !args[0].endsWith(".xsl") ) {
System.err.println("usage: XSLTransform file.xsl file.xml");
System.exit(1);
}
TransformerFactory factory = TransformerFactory.newInstance( );
Transformer transformer =
factory.newTransformer( new StreamSource( args[0] ) );
StreamSource xmlsource = new StreamSource( args[1] );
StreamResult output = new StreamResult( System.out );
transformer.transform( xmlsource, output );
}
}
Run XSLTransform, passing the XSL stylesheet and XML input, as in the following command:
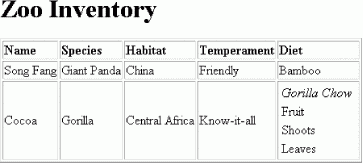
% java XSLTransform zooinventory.xsl zooinventory.xml > zooinventory.html
The output should look like Figure 23-2.
Constructing the transform is a similar process to that of getting a SAX or DOM parser. The difference from our earlier use of the TransformerFactory is that this time we construct the transformer, passing it the XSL stylesheet source. The resulting Transformer object is then a dedicated machine that knows how to take input XML and generate output according to its rules.
One important thing to note about XSLTransform is that it is not guaranteed thread-safe. If you must make concurrent transformations in many threads, they must either coordinate their use of the transformer or have their own instances.
With our XSLTransform example, you can see how you'd go about rendering XML to an HTML document on the server side. But as mentioned in the introduction, modern web browsers support XSL on the client side as well. Internet Explorer 5.x and above, Netscape 6.x, and Mozilla can automatically download an XSL stylesheet and use it to transform an XML document. To make this happen, just add a standard XSL stylesheet reference in your XML. You can put the stylesheet directive next to your DOCTYPE declaration in the zooinventory.xml file:
<?xml-stylesheet type="text/xsl" href="zooinventory.xsl"?>
Now, as long as the zooinventory.xsl file is available at the same location (base URL) as the zooinventory.xml file, the browser will use it to render HTML on the client side.
One of the most interesting directions for XML is web services. A web service is simply an application service supplied over the network, making use of XML to describe the request and response. Normally, web services run over HTTP and use an XML-based protocol called SOAP. SOAP stands for Simple Object Access Protocol and is an evolving W3C standard. The combination of XML and HTTP provides a universally accessible interface for services.
SOAP and other XML-based remote procedure call mechanisms can be used in place of Java RMI for cross-platform communications and as an alternative to CORBA. There is a lot of excitement surrounding web services, and it is likely that they will grow in importance in coming years. To learn more about SOAP, see http://www.w3.org/TR/SOAP/. To learn more about Java APIs related to web services, keep an eye on http://java.sun.com/webservices/.
Well, that's it for our brief introduction to XML. There is a lot more to learn about this exciting new area, and many of the APIs are evolving rapidly. We hope we've given you a good start.
With this chapter we also wrap up the main part of our book. We hope that you've enjoyed Learning Java. We welcome your feedback to help us keep making this book better in the future.
[1] To read Berners-Lee's original proposal to CERN, go to http://www.w3.org/History/1989/proposal.html.
| CONTENTS |